


Data science is all about using data to solve problems. The problem could be decision making such as identifying which email is spam and which is not. ... So, the core job of a data scientist is to understand the data, extract useful information out of it and apply this in solving the problems.
✅Components of Data Science
1. Big Data:
🔻The data which is huge in volume and continuously growing with the time.
🔻 E.g. The data that is generated from social media websites, emails etc.
🔻The data generated through online education portals/ shopping portals.
🔻The data generated in Stock Exchanges, banking sectors etc.
🔻The data generated by satellites.
⛔Big Data can be categorized into 3 types:
Structured data:
🔻 Highly Organised data stored in spreadsheets, database tables.
Unstructured data:
🔻 Data with no predefined structure that contains images, videos, text etc.
Semi-Structured data:
🔻 Loosely organised Data stored in XML, HTML, JSON format.

⛔Characteristics of Big Data
1. Volume:
🔻 It refers to the amount of data generated through social media, phones, satellites etc. • Distributed type of DBMS is used to store such large volume of data.
2. Velocity:
🔻 It refers to the speed at which large amount of data are being generated, collected and analyzed.
🔻 Big data allows us to analyze real time data i.e. No need to store data in database for processing.
3. Value:
🔻It refers to the worth of data being extracted. Big data is useless until we retrieve some useful information from it.
4. Variety:
🔻 It refers to the different types of data and heterogeneous sources from which data are being generated and collected.
✅Components of Data Science(contd.)
2. Data Mining:
🔻 It is a process of discovering or extracting knowledge from big data stored in multiple data sources such as files, databases, data warehouse etc.
🔻 Knowledge extracting is the process of finding related, useful or previously unknown information from big data.
✅Architecture of Data Mining

⛔Architecture of Data Mining(contd.)
1. Data Sources: Actual storage of data.
2. Different Processes:
🔻Data Cleaning is the process of detecting & removing incomplete. corrupted or inaccurate data from data source.
🔻All data is not required for processing so data selection is also necessary before passing it to the server.
3. Database or Data Warehouse Server:
🔻Server is responsible for retrieving relevant data based on data mining request of user.
4. Data Mining Engine:
🔻It consists of software to obtain knowledge and judgements from collected data.
5. Pattern Evaluation Module:
🔻• It is used to find required pattern from mined data.
6. GUI:
🔻It is communication medium between user and data mining system.
7. Knowledge Base:
🔻• It contains user experiences that might be useful to make results more accurate.
🔻 . Pattern Evaluation engine interacts with knowledge base to get inputs from it also to update it.
✅Types of Data Mining Architecture
1. No Coupling:
🔻Data mining system retrieves data from data source other than database or data warehouse, processes data using data mining algorithms and store results into the file system
🔻It does not take any advantage of database functionality
2. Loose Coupling:
🔻This system retrieves data from database or data warehouse, processes that data and stores result back to the database or data warehouse
3. Semi-tight Coupling:
🔻• This system is linked to database and data warehouse
🔻It also uses several database features like indexing, sorting, aggregation to performmining tasks
4. Tight Coupling:
🔻This system uses all the features of database and data warehouse to perform mining.
🔻 It offers high scalability and high performance
✅Data Mining Techniques
1. Decision Trees:
🔻It uses tree representation to solve problem Creates Classifier model to classify input
🔻Root node represents simple question or condition to retrieve data and to make decision
🔻Internal nodes also contains some simple question or condition
🔻Leaf node represents action to be performed


🔻Patterns are recognised based upon relationship of items in a singletransaction.
🔻E.g. Company may use association technique to research customer's buying habits, based on historical data.
3. Clustering:
🔻Classes are created as per user requirements.
4. Classification:
🔻Input data items are classified into predefined classes.
5. Prediction:
.🔻 It is used to predict results from historical data.
✅Installation of R
Following are the steps to download R
Go to www.r-project.org
Click on CRAN link to choose CRAN mirror for downloading.
Select any of the CRAN mirrors.
In Download and Install R section. Select appropriate link to download R according to you operating System.
Click on install R for the first time.
Click on Download R.
.exe file will get downloaded. Run .exe file and follow all instructions till finish.
R terminal is ready to use.
✅Installation of RStudio
Following are the steps to download R
• Go to www.rstudio.com
Click on Download.
Select Rstudio Desktop to download.
Run downloaded .exe file.
Follow all instructions till finish.


CRAN(Comprehensive R Archive Network):
CRAN is a network of ftp and web servers around the world that store identical, up-to-date, versions of code and documentation for R.
It is supported by R foundation.
R Package:
Collection of R functions, sample data sets. complied code.
Stored under directory "library".
Some packages get installed during R installation.
Packages can be installed as per requirement.

✅R Language
R is a language and environment for statistical computing and
✅graphics.
Its a GNU project.
It is different version of S language which was developed at Bell
laboratory by John Chambers and colleagues.
✅R is available as free software.
It is platform independent.
Runs on any Operating system.
It is extensible. i.e. Developers can easily write their own software and distribute it in the form of R add on packages.
R is an interpreted language.
No need to compile program into object language.
Each expression takes a form of function calls.
eg. A-2 is converted to function call as< (A.2)
✅R Language
It provides massive packages for statistical modelling, machine learning. visualization etc.
Easily produces html, pdf reports.
It has powerful meta programming facility.
# is used to give single line comment. R does not supprot multiline comments.




✅Machine Learning
Machine Learning is an application of Artificial Intelligence.
It provides computer the ability to automatically learn from past experiences, and improve system functionality without being explicitly programmed
Machine learning algorithms enable computers to learn from data set and improve themselves.
It enables software applications to predict results more accurately.
The main purpose of machine learning is to build algorithms that can receive input data and use statistical analysis to predict outcome.
Machine learning algorithm uses either labelled or unlabeled data sets as input training data.
✅There are two types of machine learning algorithms:
1. Supervised Learning:
In this algorithm, system is trained using well labelled data.
Input data is tagged with correct answer.
After training, a system is tested by providing test data set. A model is accurate if it produces correct output.
A system can easily classify new inputs observations into pre-labelled classes by determining features of input data.
It can not handle complex data sets.
It can not produce correct output if test data is different from training dataset.
Types of supervised machine learning algorithms:
1. Classification:
In this model, input data is classified in predefined ciasses.
Output is also from one of the predefined classes.
2. Regression:
This technique is mainly used to establish relationship model between two variables.
2. Unsupervised Learning:
In this algorithm, system is trained using unlabelled data. No predefined classes are present.
System creates classes by identifying similarities, differences and patterns of input data.
Types of supervised machine learning algorithms:
1. Clustering
2. Association
✅Data Analytics
Data analytics is the process of analyzing and organizing data for deriving important judgements.
Types of Data Analytics:
1. Descriptive Analysis:
It is used to identify what happened in the past?
Represented in the form of graphical visualizations.
2. Diagnostic Analysis:
. It is used to identify why did it happen? Root cause analysis.
3. Predictive Analysis:
It predicts what is likely to happen in future? Predicts future using past data.
4. Prescriptive Analysis:
It analyzes outcomes of all analytics and then allows us to make decisions based on them.
✅Data Analytics
On last Saturday, I was travelling from source A to destination B.
The distance between both the places is 20 km.
Usually it takes 20-25 minutes to reach to the destination.
But on last Saturday it took 45 minutes for me to reach to B. Descriptive analysis: on last Saturday, it took more time to reach to the
destination.
Diagnostic: It happened due to heavy traffic.
Predictive: If I follow same root on this Saturday also then again it will take more time to reach to the destination.
Prescriptive: It will be better if I try another route for travelling.
Problem solving steps in Data Science
1. Define the Problem:
Identify the problem to be solved.
2. Collecting data:
Every data driven problem solving approach needs data in a hand.
Data can be either ready to use or we need to gather data from different data sources.
3. Data Preparation:
It involves different steps like data cleaning. data selection, data integration, data analysis etc.
4. Model planning:
Decide the type of machine learning algorithm to train your system for processing.
5. Model Building:
After verifying system outcomes using different machine learning model. now we need to select one that is producing more accurate results.
6. Driving insights and generating reports:
By analyzing the outcomes/predictions produced by system, judgements can be made to solve the problem.
Judgement reports are prepared to communicate the results.
7. Taking decisions based on Insights:
Based on the judgement reports decisions can be taken to take care of problem in future.
✅Job Roles in Data Science
1. Data Scientist
2. Data Analyst
3. Business analyst
4. Statistician
5. Database Administrator
6. Data Engineer
7. Data Architect
8. Machine Learning Engineer

1. Vector:
Basic data structure.
Two types: Atomic Vector and List.
Common Properties are:
Type: typeof()
Length: length()
Atomic vectors are of four types:
Logical.
Integer.
Numeric/double,
Character.
is(): used to check whether vector is of specified type.
c(): used to combine more that one vectors.
is.NAO): used to check NA values.
Data Structures in R
Modifying vector elements:
A[2]<-3
A[A5]<-0
Delete Vector:
A<-NULL
Sorting vector:
sort(A)
sort(A, decreasing-TRUE)










Data Structures in R
seq():
It is used o generate sequence of input values.
E.g: a seq(from=1, to=10) or a-seq(1,10)
a-seq(from=1, to=10,by=2)
a-seq_len(10)
a seq(from=-5, to-5)
a-1:10
assign():
It is used to assign value to vector.
E.g. assign("a",10), assign("a", "computer")
rep():
Repeat vector values for specified number of times.
rep(a.3)
rep(a, each 3)
or rep(c(1.2),times 3)







Data Structures in R
rm():
Used to remove data object from environment.
E.g: rm(a)
scan():
It is used take input from user.
a-scan()
a scan(what-integer())
a scan(what character())
a scan(what="")
A[2]<-3
A[c(2,4)]
A[-1]

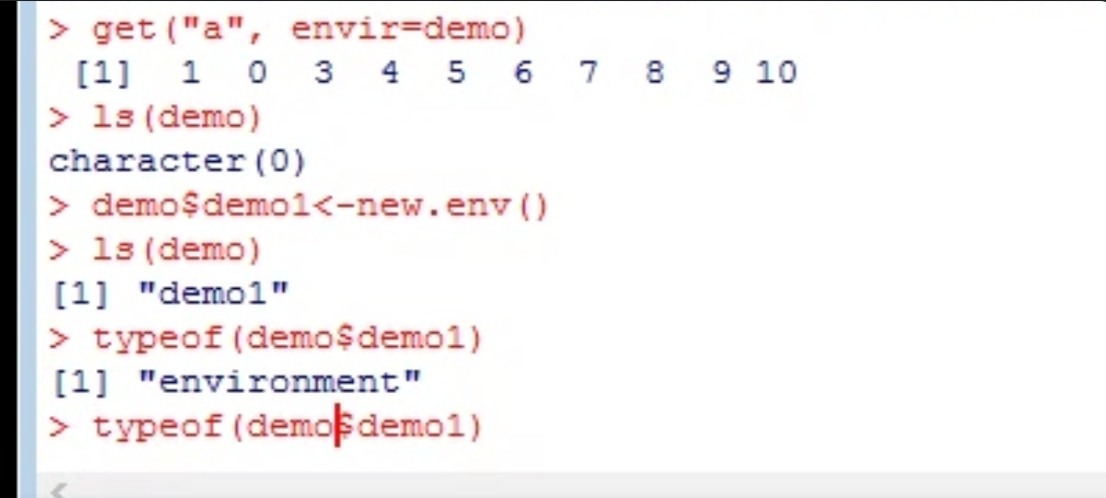
R Environment
Environment is a virtual place to store data objects.
Default Environment of R is R GlobalEnv.
environment():
get the name of the current environment. Is() is used to list out all objects created and stored under any environment.
new.env() is used to create new environment.
E.g. demo- new.env()
Creating data objects in new environment:
• demoSa -10 or assign("a". 10.envir-demo)
Is(demo)
Removing object from environment:
rm(a, envir demo)
Check whether object is present in environment:
exists("a", envir demo)
Display the value of data object from any environment:













✅Working Directory
Its a default path in computer system to store data objects and work done
When R want to import any dataset, it is assumed that data is stored in working directory.
We can have a single working directory at a time called current working directory.
getwd() is used to display current working directory.
setwd() is used to change current working directory and set new one. setwd(dir)


✅Factors in R
Factor is a data object that is used to store categorical data.
It takes only predefined types of values, called levels.
Factors components are of character type but internally they are stored as integer and levels are associated with them.
Eg shifts-factor(c("first", "second"))
typeof(shifts)
levels(shifts)
nlevels (shifts)
Directions -c("North", "South". West") Directions -factor(Directions levels c("north","south", "west", "East"))
str(Directions)
as.numeric(shifts)
as.character(shifts)

✅Array in R
Its a multidimensional data structure.
1D array is a vector, 2D array is matrix.
Creating array:
VI<-c(1,2,3)
V2<-c(4,5,6)
A-array(c(V1.V2). dim c(3,3))
A-array(c(V1.V2), dim=c(3,3,2))
A(1:4,dim c(2.2))
Assigning names to rows and columns:
column.names=c("cl,"c2","c3")
row.names=c("rl, "r2", "r3") matrix.names=c("ml, "m2")



✅Array in R
Access array elements:
print(A[2.3]) prints element at 2nd row and 3rd column.
print(A[2.3.1]) prints element at 2nd row and 3rd column from 1st matrix.
print(A[2.3. ]) prints element at 2nd row and 3rd column of both matrix.
print(A[1])
:prints first matrix.
print(A[ 1..]) prints first row of both matrix. print(A[2.1]) prints 2nd column of matrix 1.
Modify array elements:
A[1.1.1] -0
:set element at 1s row and Is column to 0.
A[A 3] -0 :set all array elements that are 3 to 0.







{kind=link}
0 Comments